Nexus
Implementation od the NEXUS model from Leveraging hierarchy in multimodal generative models for effective cross-modality inference.
This model uses two levels of latent variables : the first level is modality-specific \(z_i\) ans the second level is shared \(z_{\sigma}\).
The diagram below illustrate the architecture of this model:
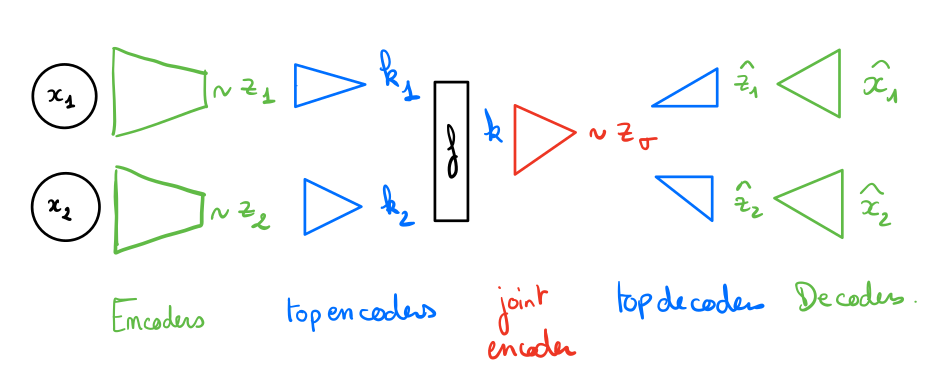
The loss of the model is the sum of the bottom loss (composed of M multimodal ELBOs):
and the top loss
The \(\beta, \beta_i, \lambda_i,\gamma_i\) factors weighs the different terms. This model further uses annealing at the beggining of training. The Nexus model further uses a Forced Perceptual Dropout paradigm where during training, some modalities are dropped before computing the top loss.
Note
This model can be used in the partially observed setting, by simply summing on available modalities for sample \(X\).
Note
We didn’t manage to reproduce the results presented in the paper for this model, although we followed the article and the official implementation closely. If you notice an error in our implementation, don’t hesitate to reach out to us.
- class multivae.models.NexusConfig(n_modalities, latent_dim=10, input_dims=None, uses_likelihood_rescaling=False, rescale_factors=None, decoders_dist=None, decoder_dist_params=None, custom_architectures=<factory>, modalities_specific_dim=None, bottom_betas=None, dropout_rate=0, msg_dim=10, aggregator='mean', top_beta=1, gammas=None, warmup=20, adapt_top_decoder_variance=None)[source]
This is the base config for the Nexus model from (Vasco et al 2022).
- Parameters:
n_modalities (int) – The number of modalities. Default: None.
latent_dim (int) – The dimension of the latent space. Default: None.
input_dims (dict[str,tuple]) – The modalities’names (str) and input shapes (tuple).
uses_likelihood_rescaling (bool) – To mitigate modality collapse, it is possible to use likelihood rescaling. (see : https://proceedings.mlr.press/v162/javaloy22a.html). The inputs_dim must be provided to compute the likelihoods rescalings. It is used in a number of models which is why we include it here. Default to False.
rescale_factors (Dict[str, float]) – The reconstruction rescaling factors per modality. If None is provided but uses_likelihood_rescaling is True, a default value proportional to the input modality size is computed. Default to None.
decoders_dist (Dict[str, Union[function, str]]) – Per modality, you can provide a string in [‘normal’,’bernoulli’,’laplace’]. For Bernoulli distribution, the decoder is expected to output logits. If None is provided, a normal distribution is used for each modality.
decoder_dist_params (Dict[str,dict]) – Parameters for the output decoder distributions, for computing the log-probability. For instance, with normal or laplace distribution, you can pass the scale in this dictionary with
decoder_dist_params = {'mod1' : {"scale" : 0.75}}.modalities_specific_dim (Dict[int]) – dimensions of the first level latent variables for all modalities, noted at z^(i) in the paper. Default to None
bottom_betas (dict[str, float]) – hyperparameters that scales the bottom modality-specific KL divergence.
dropout_rate (float between 0 and 1) – dropout rate of the modalities during training. Default to 0.
msg_dim (int) – Dimension of the messages from each modality. Default to 10.
aggregator (Literal['mean']) – Default to ‘mean’
top_beta (float) – parameter that scales the KL of the higher level ELBO. Default to 1.
gammas (Dict[str, float]) – each top-level representation of each modality.
rescale_factors – each modality. Correspond to the lambda factors in the appendix of the paper.
warmup (int) – number of epochs for the annealing of the KL terms in the loss. Default to 20.
adapt_top_decoder_variance (List['str']) – For the listed modalities adapt the scale of the top decoders using the procedure cited in https://arxiv.org/pdf/2006.13202 . Default to [].
- class multivae.models.Nexus(model_config, encoders=None, decoders=None, top_encoders=None, joint_encoder=None, top_decoders=None, **kwargs)[source]
The Nexus model from (Vasco et al 2022) “Leveraging hierarchy in multimodal generative models for effective cross-modality inference”.
- Parameters:
model_config (NexusConfig) – An instance of NexusConfig in which any model’s parameters is made available.
encoders (Dict[str, BaseEncoder]) – A dictionary containing the modalities names and the encoders for each modality. Each encoder is an instance of ~pythae.models.nn.BaseEncoder
decoders (Dict[str, BaseDecoder]) – A dictionary containing the modalities names and the decoders for each modality. Each decoder is an instance of ~pythae.models.nn.BaseDecoder
top_encoders (Dict[str, BaseEncoder]) – A dictionary containing for each modality, the top encoder to use.
joint_encoder (BaseJointEncoder) – The encoder that takes the aggregated message and encode it to obtain the high level latent distribution.
top_decoders (Dict[str, BaseDecoder]) – A dictionary containing for each modality, the top decoder to use.
- decode(embedding, modalities='all', **kwargs)[source]
Decodes the embeddings given by the latent function.
- encode(inputs, cond_mod='all', N=1, return_mean=False, **kwargs)[source]
Generate encodings conditioning on all modalities or a subset of modalities.
- Parameters:
inputs (MultimodalBaseDataset) – The dataset to use for the conditional generation.
cond_mod (Union[list, str]) – Either ‘all’ or a list of str containing the modalities names to condition on.
N (int) – The number of encodings to sample for each datapoint. Default to 1.
return_mean (bool) – if True, returns the mean of the posterior distribution (instead of a sample).
- Returns:
z (torch.Tensor (n_data, N, latent_dim)) one_latent_space (bool) = True
- Return type:
ModelOutput instance with fields