MHVAE
- Multimodal Hierarchical Variational Autoencoder from
‘Unified Brain MR-Ultrasound Synthesis using Multi-Modal Hierarchical Representations’ (Dorent et al, 2O23) (https://arxiv.org/abs/2309.08747).
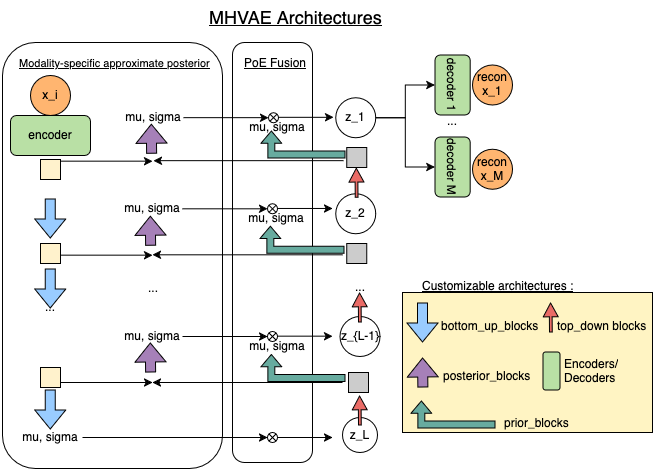
The MHVAE is a hierarchical VAE that can handle multiple modalities. The latent variable is partitioned into disjoint groups \(z = \set{z_1, z_2, ..., z_L}\) where L is the number of levels.
The prior on the latent variables is defined as:
\[p_{\theta}(z) = p_{\theta_L}(z_L)\prod_l p_{\theta_l}(z_l|z_{>l})\]where \(z_{>l}\) denotes the latent variables at levels higher than l.
The posterior is defined as \(q_{\phi}(z|x) = \prod_l q_{\phi_l}(z_l|x,z_{>l})\) that approximates the intractable true posterior \(p_{\theta}(z|x)\).
At each level l, the posterior \(q_{\phi_l}(z_l|x,z_{>l})\) is approximated by a Product-of-Experts. At the deepest level, \(q_{\phi_L}(z_L|x) = p_{\theta_L}(z_L) \prod_i q_{\phi_L^{i}}(z_L|x_i)\). At following levels, \(q_{\phi_l}(z_l|x,z_{>l}) = p_{\theta_l}(z_l|z_{>l}) \prod_i q_{\phi_l^{i}}(z_l|x_i,z_{>l})\).
Some weights are shared between the different posteriors and priors distribution. To allow flexibility while remaining close to the original implementation, we describe customizable blocks in diagram below. (adaptated from the diagram in the original paper)
Note
In the original paper, the authors use a discriminator loss to improve the quality of the generated samples. This block is not yet implemented in this version of the code.
- class multivae.models.MHVAEConfig(n_modalities, latent_dim=10, input_dims=None, uses_likelihood_rescaling=False, rescale_factors=None, decoders_dist=None, decoder_dist_params=None, custom_architectures=<factory>, n_latent=3, beta=1.0)[source]
This is the configuration class for the Conditional Variational Autoencoder model.
- Parameters:
n_modalities (int) – The number of modalities. Default: None.
latent_dim (int) – The dimension of the latent space. Default: None.
input_dims (dict[str,tuple]) – The modalities’names (str) and input shapes (tuple).
uses_likelihood_rescaling (bool) – To mitigate modality collapse, it is possible to use likelihood rescaling. (see : https://proceedings.mlr.press/v162/javaloy22a.html). The inputs_dim must be provided to compute the likelihoods rescalings. It is used in a number of models which is why we include it here. Default to False.
rescale_factors (dict[str, float]) – The reconstruction rescaling factors per modality. If None is provided but uses_likelihood_rescaling is True, a default value proportional to the input modality size is computed. Default to None.
decoders_dist (Dict[str, Union[function, str]]) – Per modality, you can provide a string in [‘normal’,’bernoulli’,’laplace’]. For Bernoulli distribution, the decoder is expected to output logits. If None is provided, a normal distribution is used for each modality.
decoder_dist_params (Dict[str,dict]) – Parameters for the output decoder distributions, for computing the log-probability. For instance, with normal or laplace distribution, you can pass the scale in this dictionary with
decoder_dist_params = {'mod1' : {"scale" : 0.75}}.n_latent (int) – the number of latent variables.
beta (float) – the weight for the KL divergence.
- class multivae.models.MHVAE(model_config, encoders, decoders, bottom_up_blocks, top_down_blocks, posterior_blocks, prior_blocks)[source]
MHVAE model.
- Parameters:
model_config (MHVAEConfig) – the model configuration.
encoders (Dict[str,BaseEncoder]) – contains the first layer encoder per modality.
decoders (Dict[str, BaseDecoder]) – contains the last layer decoder per modality.
bottom_up_blocks (Dict[str, list]) – For each modality, contains the (n_latent-1) bottom-up layers. Each layer must be an instance of nn.Module. The last layer must be an instance of BaseEncoder and must return the mean and log_covariance for the deepest latent variable.
top_down_blocks (List[nn.Module]) – contains the (n_latent-1) top-down layers. Each layer must be an instance of nn.Module.
posterior_blocks (List or Dict) – contains the (n_latent - 1) posterior layers for each modality. Each layer must be an instance of BaseEncoder. The input dimension of each posterior block must match 2 * the output dimension of the corresponding top_down_blocks. Provide a list if the weights are shared between modalities, and a dictionary if they are not.
prior_blocks (List) – contains the (n_latent - 1) prior layers. Each layer must be an instance of BaseEncoder. The input dimension of each prior block must match the output dimension of the corresponding top_down_blocks.
- check_and_set_posterior_blocks(posterior_blocks)[source]
Check the coherence of the posterior_blocks with the model configuration.
- encode(inputs, cond_mod='all', N=1, return_mean=False, **kwargs)[source]
- Encode the input data conditioning on the modalities in cond_mod
and return the latent variables.
- Parameters:
inputs (MultimodalBaseDataset) – the input data.
cond_mod (str, list) – the modality to condition on. Either ‘all’ or a list of modalities.
N (int) – the number of samples to draw from the posterior for each sample. Generated latent_variables will have shape (N, n_data, n_latent)
return_mean (bool) – if True, returns the mean of the posterior distribution (instead of a sample).
- Returns:
a ModelOutput instance containing the latent variables.
- Return type:
ModelOutput
- forward(inputs, **kwargs)[source]
Compute the average negative ELBO loss using all possible subsets of modalities for the posterior.
- Parameters:
inputs (MultimodalBaseDataset) – the input data.
- Returns:
a ModelOutput instance containing the mean loss and the KL divergences for monitoring.
- Return type:
ModelOutput
- modality_encode(data)[source]
Encode each modality on its own.
- Parameters:
data (Dict[str, torch.Tensor]) – the input data for each modality.
- Returns:
- a dictionary containing for each modality a ModelOutput instance
with embedding and logcovariance.
skips : a dictionary containing a list of tensors for each modality.
- Return type:
z_Ls_params
- sanity_check_bottom_up(encoders, bottom_up_blocks)[source]
Check the coherence of the bottom_up_blocks with the encoders.
- sanity_check_prior_blocks(prior_blocks)[source]
Check the coherence of the prior_blocks with the model configuration.
- sanity_check_top_down_blocks(top_down_blocks)[source]
Check the coherence of the top_down_blocks with the model configuration.
- subset_encode(z_deepest_params, skips, subset, inputs, return_mean=False)[source]
Compute all the latent variables and KL divergences for a given subset of modalities.
- Parameters:
z_deepest_params (Dict[str, ModelOutput]) – dictionary containing the mean and logvar of the deepest latent variable for each modality.
skips (Dict[str, List[torch.Tensor]]) – dictionary containing the intermediate results of the bottom-up layers for each modality.
subset (List[str]) – list of modalities to consider to compute the joint posterior.
inputs (MultimodalBaseDataset) – the batch data.
return_mean (bool) – If True, we return the mean everytime we sample from a distribution. Default to False.
- Returns:
dictionary containing all the latent variables at each level. kl_dict (Dict[str, torch.Tensor]): dictionary containing all the KL divergences at each level.
- Return type:
z_dict (Dict[str, torch.Tensor])