Case Study 2
Benchmark models on the Incomplete PolyMNIST dataset
In this case study, we demonstrate how MultiVae can be used to perform a benchmark of models on a complex scenario.
We evaluate 6 models on the Incomplete PolyMNIST dataset with three levels of missing data:
η = 1 : no missing data
η = 0.8 : 20% of missing data
η = 0.5 : 50% of missing data
To reproduce this case study, all you need is to have MultiVae installed and the scripts in this folder.
Note on the structure of the code: in global_config.py, we define all the shared parameters, architectures and datasets that we use as well as the evaluation pipeline using MultiVae metrics modules.
Reproduce the benchmark
First, set the paths in global_config.py:
# Set your paths
DATA_PATH = '/home/{your_path}/data'
SAVE_PATH = '/home/{your_path}/experiments/benchmark_on_partial_mmnist'
If you use MultiVae to download the PolyMNIST dataset, then you don’t have to change the CLASSIFIER_PATH/ FID_PATH: the classifiers and fid model are downloaded along the dataset and the path are correctly set.
To launch an experiment run a command like the one below:
python {insert_model_name}.py --keep-incomplete --seed {insert_seed} --missing_ratio {insert missing ratio}
Replace the brackets with the arguments of your choice. Here are the options:
For the model_name :
jmvae,jnf,mvae,mmvae,mvtcae,mopoe,mvae--keep_incomplete: use this argument to keep all the data even samples with missing modalities--missing_ratio: either 0, 0.2 or 0.5--seed: the seed for the experiment.
Example:
python mvtcae.py --keep-incomplete --seed 0 --missing_ratio 0.2
trains the MVTCAE model on a partial dataset with 20% of missing data but keeping incomplete samples in the mix.
Note that for jmvae, jnf, the option –keep_incomplete can not be used as these models are incompatible with missing data.
And there you go! You have everything to reproduce the experiments.
Results
You can visualize all results on this wandb workspace : https://wandb.ai/multimodal_vaes/compare_on_mmnist
We also downloaded metrics from this wandb workspace to do our own plots: (if you go to /runs, you can download everything in a csv format).
Below are the coherences results that we obtained:
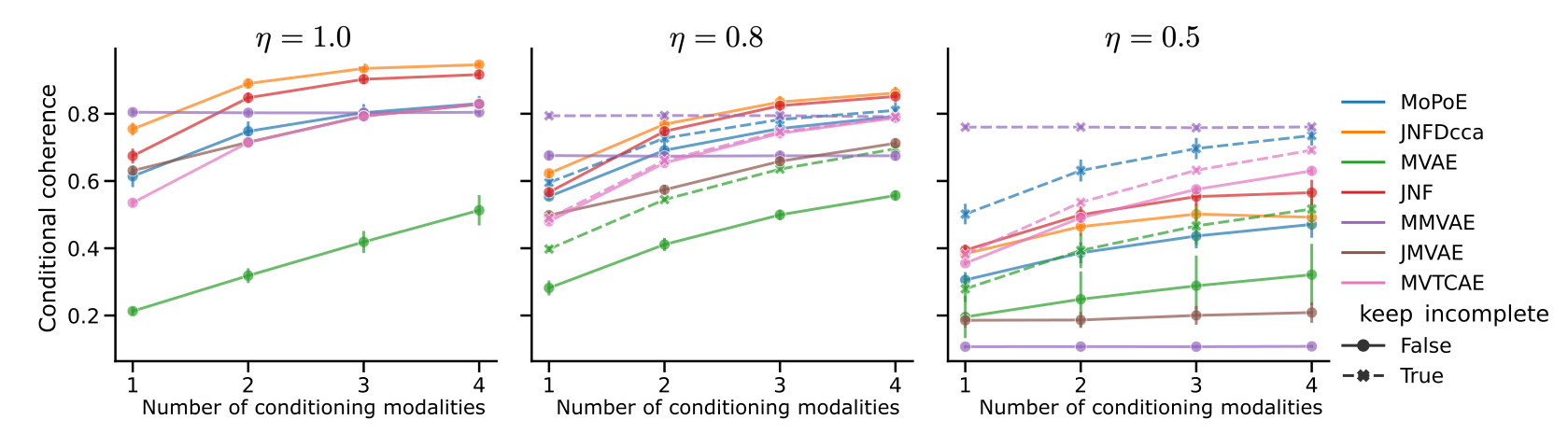 The MoPoE, MMVAE and MVTCAE performances hold surprisingly well to large percentages of missing data!
The MoPoE, MMVAE and MVTCAE performances hold surprisingly well to large percentages of missing data!
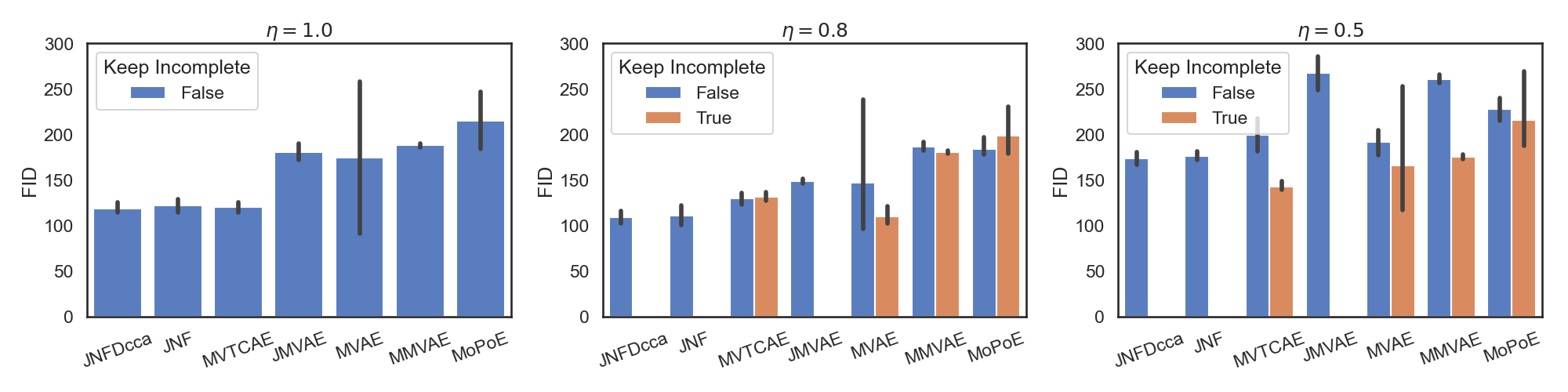
We also compared the FID values:
Additional Analysis of the models
All the models trained for this case-study are available on HuggingFace.
If you want, you can run additional analysis on these models by reloading them.
Load trained models and compute clustering metrics
To compute clustering metrics with the trained models available on HuggingFaceHub, you can run
python clustering.py --model_name {insert model name} --seed {insert seed} --keep_incomplete --missing_ratio {insert_missing_ratio}
Example:
python clustering.py --model_name MMVAE --seed 0 --keep_incomplete --missing_ratio 0.2
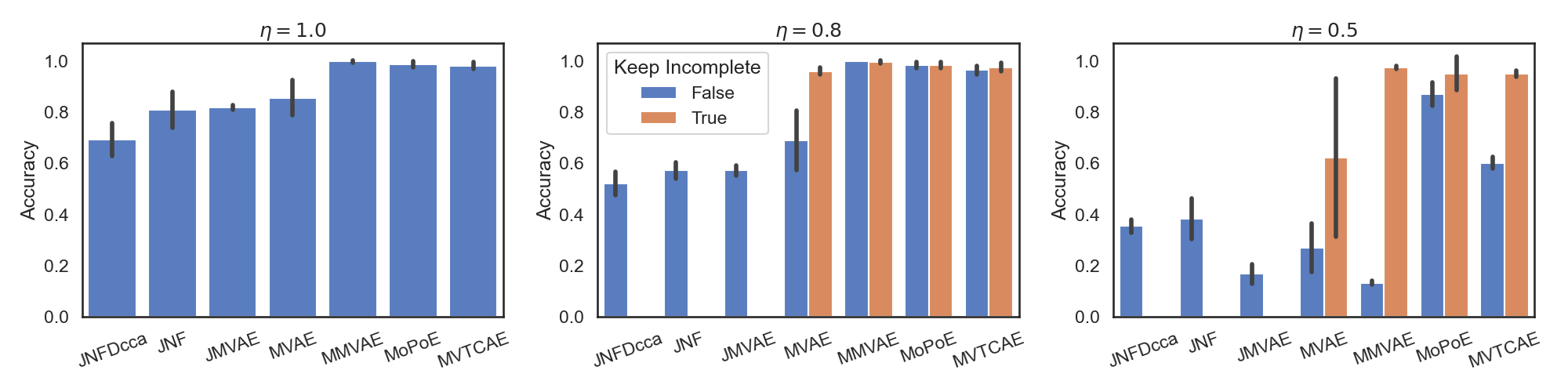
With this script, we can compute all clustering accuracies and obtain the following results:
Load trained models and analyse joint generation with samplers
With the script samplers.py you can reload the models to compute the joint coherence with different samplers.
python samplers.py --model_name {insert model name} --seed {insert seed} --keep_incomplete --missing_ratio {insert_missing_ratio}
Example:
python samplers.py --model_name MMVAE --seed 0 --keep_incomplete --missing_ratio 0.2
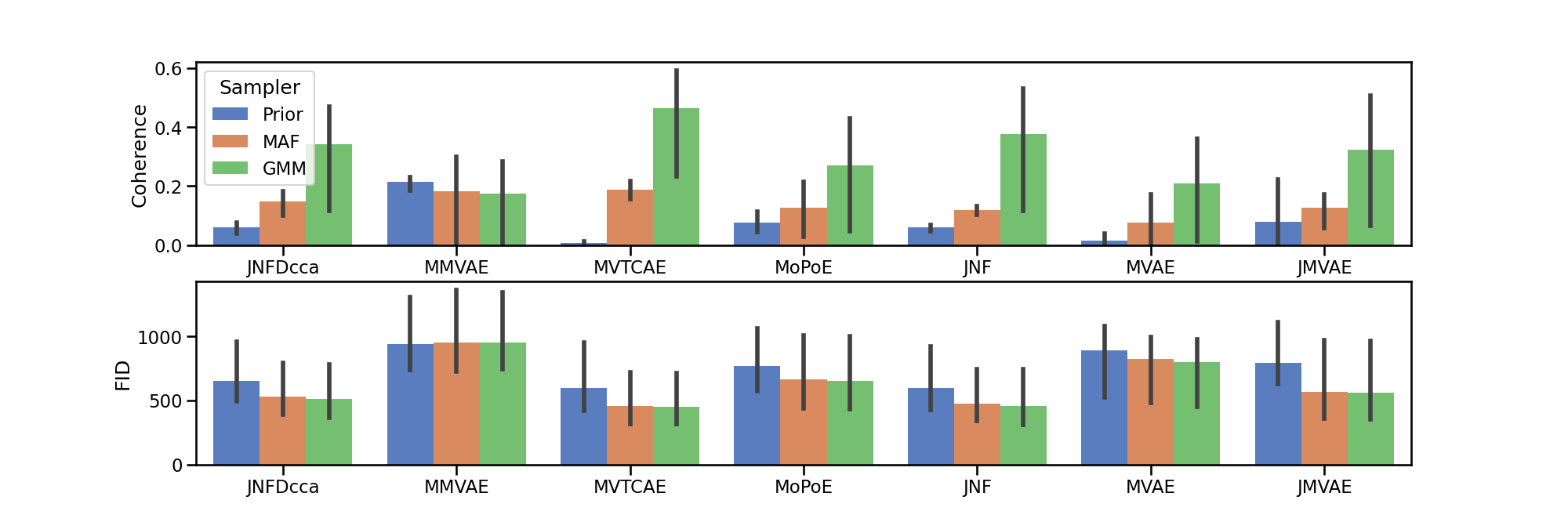
With this script, we can explore how the joint coherence/FID varies when we change samplers:
Questions ?
We hope you enjoyed this example and don’t hesitate to reach out to us if you have any issue/question ! contact : agathe.senellart@inria.fr